After this first version of the NN and lastly the visualization of the evolution of the NN during its training, it’s time for me to move on to a whole new approach, with the main lines of which are as follows.
Constat and context:
If I refer to the choices I had to make when beginning with the SW design in Armory for a relatively big application and requiring speed, I would say that I was brought to adopt an “object composition” approach in OOP because of the existence of the Node trees editor, either graph structures and the sequences it allows for example (cf. In/Out of nodes, Events, Set property,…).
I compare this result with the one I would have had with a programming only in Haxe, that would have led me to a “class inheritance” approach, much more OOP.
However, currently, the core is built as a matrix of matrix of matrix with maths applied on it, and performance at execution is excellent.
Another constat is that the spaggethi design inside lot of Node trees I made, makes things difficult to maintain and reuse. I have improved things by establishing quality rules such as naming, for example, to help me find my way around. Thus I think that creating for exemple a game, and especially if the development team is large, by in first providing a major upstream effort in terms of quality rules, according to this approach would also lead to a better experience.
Another constat is a lacke in this first version of ATRAP, that is the possibility to dynamically cut/set links between neurones during execution of the training, according to certain strategies. I think this could become fundamental for new generations of Neural Networks and architectures.
Then because of the Events and Set Property I used a lot in last version of ATRAP, the next OOP design evolution I am considering is based on a “Subject / Observer” approach.
Neurones and Layers as Subject/Observer :
In this case for exemple inside the Neural Network, all observer neurons, as registered observers of other neurons, are notified and upgraded automatically when the subject neuron changes state. The same applies to Layers like the Input, x Hiddens, Output Layers.
(that is to compare to a standard approach that could consists in a Neural Network instance that iterates through every connection between Neurons in every Layer into the Neural Network)
If there is one improvement I intend to achieve, it’s in the evolution capacities in dynamics, cad suppression/addition of Observer or Subject to discover new behavior in NN and thus improve as never before, the dynamic transformation of the architecture of the NN in training according to the <State, Action, Reward> and the evolution of the Loss and Variance.
This may lead to exploring innovative other approaches for new generations of NNs with more software/computer-based and less mathematical methods of managing things like backpropagation within the NN. I think that this concept could lead to the possibility of creating a meta-intelligence within the NN.
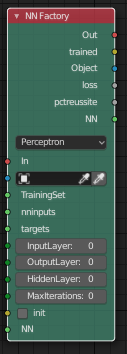 An important node of ATRAP is the “NN Factory”. It would then become an intelligent and dynamic “NN Architect Factory”.
An important node of ATRAP is the “NN Factory”. It would then become an intelligent and dynamic “NN Architect Factory”.
The discussion here Communication between objects about OOP with @zicklag reflects how things are in progress too, like with his last Call Function Logic nodes and his idea of the possibility to create a new “Class” logic node and a special workflow for creating “Classes” to allow a more easy OOP approach in Armory.
Objectives of the next version, like in a radar tracking
I hope that this new version of ATRAP will allow to explore new generations of NNs and according new dynamically reconfigurable architectures.
I also think that this could open new doors, like with the similarities that exists between the physics of matter, signal processing and Neural Networks, which could be then be more easily observed with this type of improvement in ATRAP.
For example, one of the paths I plan to explore is the example of what we find in signal processing with the arrival of FFT. (The most classic use of the Cooley-Tukey algorithm, for example, is a division of the transformation into two parts of identical size n/ 2 at each step.) We can very well imagine that the dynamic transformation of the NN is of this type, with partitioning, increasing or reducing the mass of neurons/layers during learning, that is at each step “t” as in this schema
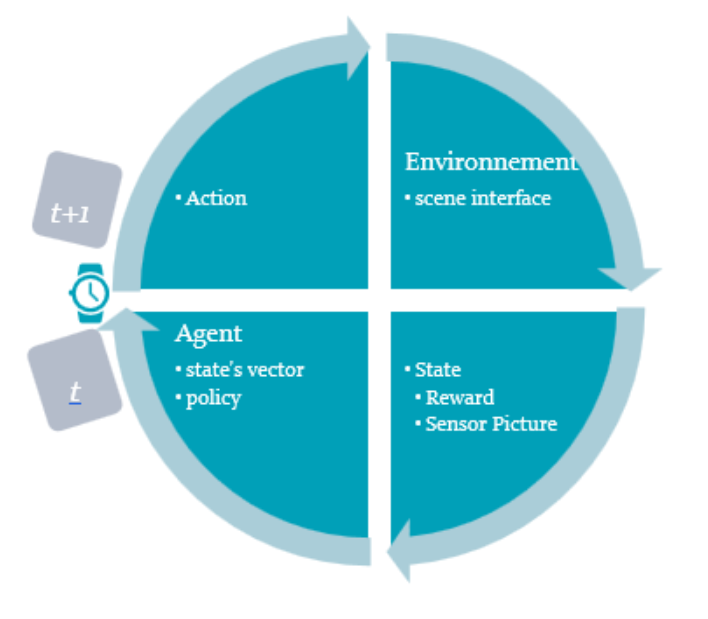
The dynamic is combined with a kind of Kalman filter (this filter estimates the states of a dynamic system from a series of incomplete or noisy measurements. This is typically the case with NN/Layers/neurons).
This would involve thus a new concept in NN training that I share here for the first time, which is to use a “dynamic of a Layer”, which defines a form of evolution over time of the Layer (like with a target in a radar system).
Actual NN update each neurone during training, but not the Layers architecture. This is where I think to use a kalman filter to obtain the better NN architecture from step t to step t+1, by comparaison of the estimated loss/gradient descent and after the update of the NN. Thus it could enable to eliminate the effect of noise/bad input data as well as bad gradient descent during the training of the NN (cf. gradient-based learning methods and backpropagation). As learning and retrieval are not two independent operations, the Layer structure can then be calculated for the moment, in the past or on a future horizon, just like what is done in radar tracking software. With this prediction, output estimate of a state could be done according to a dynamic Layers ajustement.
To give you a representative image: it’s as if you have a window that you narrow when your target is well detected at a position and you enlarge if you have lost it, thus to find it and hang it up again. A thing that can be very practical in some games to reduce calculations.
With NN, this is a little bit the case with an NN that clings well with a low loss, versus it starts to deviate from the good predictions. The underlying idea is then that shrinking / enlarging the size of Layers can be comparable to changing the size of the window in radar tracking. Thus the ideal is to use as small as possible Layers in order to limit CPU usage during the training and then, but less important, during interrogation…
2019-06-11T22:00:00Z Some News: Using the proposed OOP approach in Armory seems very promising for the readability and simplification of large applications. ( see here for first steps using the proposed OOP approach Communication between objects )

Secondly the NN is now designed to be dynamic and I think to be able to test very interesting things using this new capability that I didn’t already found elsewhere in scientific parutions … a little bit as if one were to move from a frozen architecture NN to an NN capable of metamorphosing according to events.