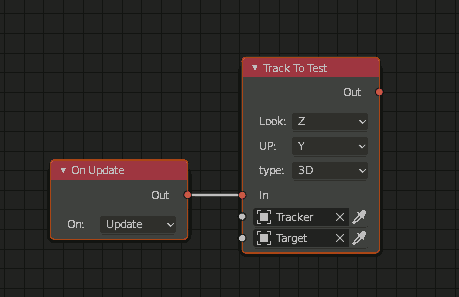
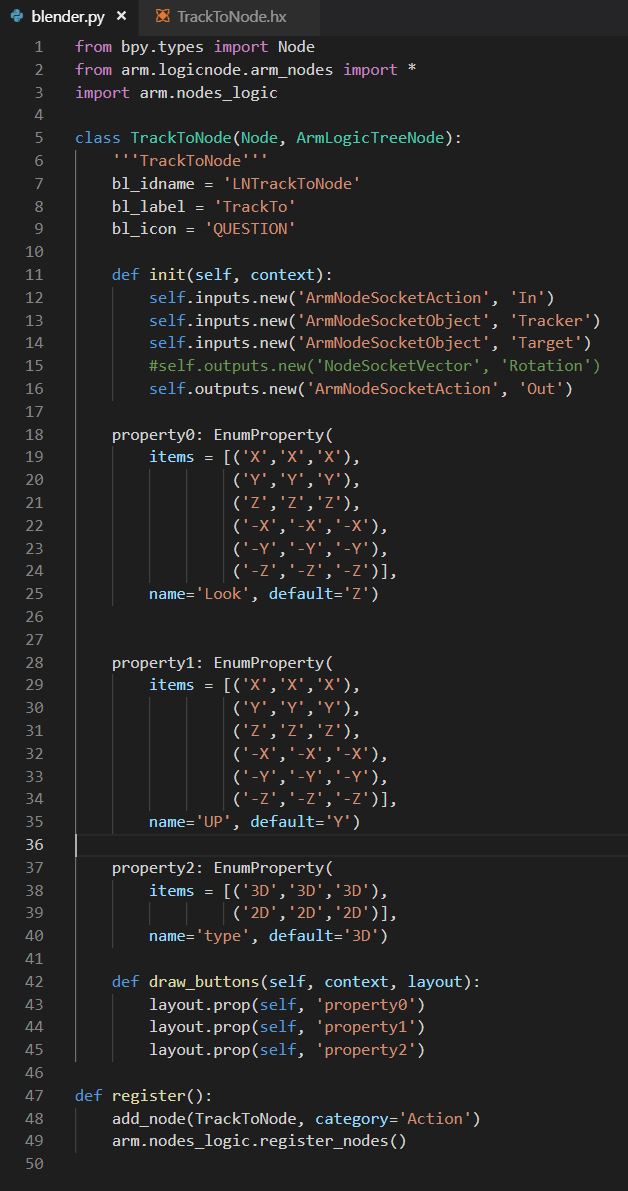
TL;DR: The “strangeness” comes from the conversion between euler angles and quaternions. In the node you see (x,y,z) to represent the rotation but internally is using (a,b,c,d) to perform the calculations because is more convenient and is not affected by issues like gimbal lock. But this has a problem, the conversion back from (a,b,c,d) to (x,y,z) has multiple results (or representations), and is complicated to guess what was the result the user expected.
When you want to rotate something there is a conversion from the input of the user (x,y,z)(Euler angles) to (a,b,c,d)(Quaternion). After converting to (a,b,c,d) the calculations are done to perform the rotation and then the result is converted back to (x,y,z) for the user to see.
The problem comes when converting back from (a,b,c,d) to (x,y,z): There are multiple representation for (a,b,c,d) in (x,y,z), that is the result you expected and the result you got.
You can obtain both internally but the problem is guessing what was the result the user expected.
Some stuff can be done to aid this issue but they are not perfect and still break, you can test this yourself in more mature engines that rotation using (x,y,z) in multiple angles can break too!
So it’s a presentation vs usability problem. The rotation nodes and the Transform could be modified to instead of using (x,y,z) uses (a,b,c,d) directly and the problem would be gone, but you will loose the “convenience” of (x,y,z).
Some engines prefer simply to encourage using quaternion instead of (x,y,z) to solve the issue.
A solution would be, modifying the lookAt node to return a value of (a,b,c,d), skipping the conversion, and then the Transform node could be changed to receive (a,b,c,d) instead of (x,y,z) and that would solve the issue I think. The problem is if the user has no issue not seeing (x,y,z) anywhere.
I will try later to post here some modified version of the nodes to test it.