@Didier can I ask, are you using any python libraries behind this or reimplementing entirely in haxe?
I’ve been recently learning PyTorch so was curious.
@Didier can I ask, are you using any python libraries behind this or reimplementing entirely in haxe?
I’ve been recently learning PyTorch so was curious.
@AnadinX
Everything is in Haxe and not coming from Python library … the simplest and small code as possible to do it.
As Lubos wrote “Behind the scenes, Armory is powered by open-source technology. Utilizing Kha - multimedia framework and Haxe - cross platform toolkit, to provide top class performance and portability. “ and it is mandatory for me to stay in line with that … look in the forum at what I suppose those who could participate to a kind of ecosysteme are also waiting for.
For the moment, I need to find a successful way to easily acquire the camera view in Armory, transform it into an array of pixels and feed the NNA with it (the Armory code doesn’t seem to me to be complete right now to do this and I hope @Lubos will now have more time after delivering the 0.4 release to address the issue).
Thus with NNA, tests are already done with small matrix representing ASCII characters and performances are at rendez-vous thanks to the NNA logic nodes coded all only in haxe, focused on only one thing : near real time performances to simulate reality + portability on different kinds of small platforms.
For your information, during this time I progress also on the realization of other logic nodes which will allow us to realize interesting things on the one hand for games, but also for real applications. Thus @AnadinX if you are learning Pytorch, I propose to you to focus on this example in Pytorch https://pytorch.org/tutorials/intermediate/reinforcement_q_learning.html#sphx-glr-intermediate-reinforcement-q-learning-py to better understand what the following logic nodes mean.
I take the example of the fireman who must move as quickly as possible through a burning building. He obviously has not the time to assimilate all the building’s plans and cannot memorize all the evolutions of his environment given in real-time by sensors and others field actors. For example, a hearing aid could indicate the best options at any time according to current needs (find, escape, etc.) and constraints (remaining oxygen, temperature, obstacles, etc.). They operate in an environment for which we will only know later if it was the right decision he took and so where it can be difficult at a given time to understand what action leads to what result through many successful steps according to given targets, and each of which can be decisive for the final result. We find the same problem for industrial processes that lead to quality defects and rejects, and it’s a challenge for the enterprise 4.0.
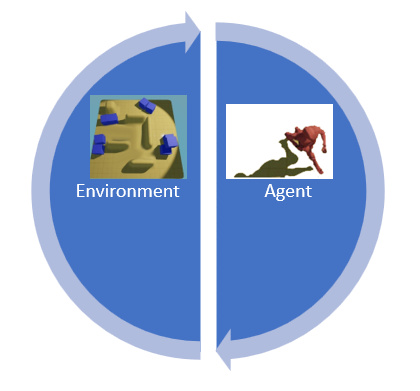
We will have a logic node for the Environment that is able to transform an action taken by the 3D character in the actual state into the next state and a reward. The logic node for the 3D character (Agent) transforms to a new state and reward into the next action.
Thus, to simplify for the fireman, the first step for me is to modelize in Armory some kind of simple evacuation of a character from any room in the building. This is the objective of what is called in Machine Learning jargon, Reinforcement Algorithms that incorporate Deep Learning like the actual NNA.
Thus the NNA  will become a kind of Expert, pre-trained. With several of those agents specialised in sub-tasks (imagine one agent for one sensor (vision, IR, doppler, gaz, Tp, RFID, IoT com, …), we get what is called a policy that can map a state to a best action according to what the NNA Expert Agent is trained for.
will become a kind of Expert, pre-trained. With several of those agents specialised in sub-tasks (imagine one agent for one sensor (vision, IR, doppler, gaz, Tp, RFID, IoT com, …), we get what is called a policy that can map a state to a best action according to what the NNA Expert Agent is trained for.
I expect that if an ecosystem around NNA is growing and that step by step this ecosystem develops useful solutions to achieve real-world objectives by playing with the NNA logical node to create awwesome architectures for reinforcement learning , operating better and better in simulated and random harsh environments like in video games and then worn in the real world ( and thus do not remain limited to the video game  ).
).
Maybe the core of allowing a fast growing ecosystem is to allow via and thanks to easy use of the logic nodes inside Armory to formalize a knowledge transfer mechanism which allows a new coming player in the network to exploit access to a kind of cloud/lake of Expert Agents, becoming the teachers. The role of the ecosystem administrator becomes to be in charge to validate when an Agent is becoming an Expert of what and then put it into the Expert NNA Cloud. The role of a NNA Switcher logic node then becomes to make/assure the best automatic connection between an Actor/Environnement needs and the Experts available in the Expert NNA Cloud.
To complete and for those interested with the preceeding post with actors/ environment/ teachers, I propose you to visit and test the DeepMind Lab which provides a suite of challenging 3D navigation and puzzle-solving tasks for learning agents. Primary purpose is to act as a testbed for research in deep reinforcement learning, it can give you an idea of what we can do and simplify/favorize creativity of the community by the use of logic nodes in Armory.
This preliminary design of logic nodes for a Deep Reinforcement Learning Armory (DRLA) is made according to the following requirements 
GENERAL:
Now we don’t need to build a json file filled with labeled training data (like we do with the actual NNA).
The Agent will interact a lot of times with the Environment (during rounds) and we observe positive and negative experiences during those experimentations. It’s like the imitation we have done with the NNA.
We figure that our Environment modifies from state s to state s’, following action a. The immediate reward we observe in the environment is r. Our objective is for a current state s, to estimate from all possible actions which action will give the maximum immediate reward plus future best rewards.
That’s the expected reward taking the action a in state, the Q(s,a), named the Q-function.

Q(s,a) = r + γ * Q(s’,a’) where γ is a factor for future uncertainty.
DEFINING ARMORY LOGIC NODES CAPABILITIES FOR DEEP Q-LEARNING
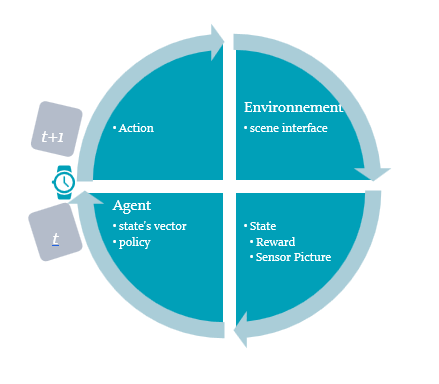
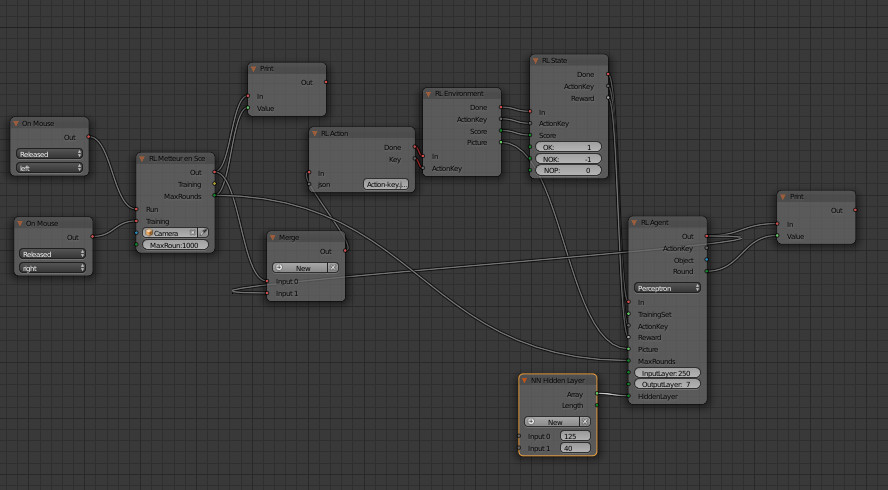
Taking the example of the tanks game, thereafter the main nodes for the DRLA (Deep Reinforcement Learning Armory).

Action: the possible actions are: move_right, move_left, move_front, move_back, wait, canon_up, canon_down, fire;
Environnement: gets the action and modifies the scene; takes a picture of the 3D scene with the selected sensor, that’s here a camera; modifies the game’s score.
State: the scene interface gives the sensor picture of the scene at t and the game score. The Reward becomes: If the action = fire and the game score increases, then reward r = 1; Missing the target when fire makes score not changing or decreasing and r = -1; moving right, left or wait makes r = 0.
Agent : the sensor picture is transformed into an input vector for the Agent’s NNA, the State’s vector; given an input state vector, the NNA predicts rewards for all 8 actions. The Action with the best reward is selected for the following t+1 round.
DRLA (Deep Reinforcement Learning Armory) preliminary design of the logic node system:
promising and to test in the futur with DRLA to discover all the potential, those new robots are mergeable in nervous system (MNS) of devices.
If you have a 3D printer, it’s then interesting to imagine make the link between a trained DRLA in Armory and those reality within your reach (Open-Source)
with a robotic arm https://github.com/NiryoRobotics/niryo_one
or with the InMoov robot
last info : thereafter the new preliminary design of the DRLA logic nodes system.
The main design evolutions concern the RLAgentTraining and the RLAgentActive.
The Send Event send the adhoc event to the tank game and Scoredujeu retreive the actual game score.
The RL Metteur en Scene is the starting point for the training/activation of the Deep Reinforcement Learning.
Next step will be to start tests with the game tanks and it’s going to be exiting
@AnadinX @lubos @donalffons @NothanUmber @wilBr
Wow! Push the button!
Yes ! The fun part coming soon 
@Didier this looks fantastic - hit me up if there is anything I can do to help even though its more likely I’ll just be learning from you 
@AnadinX for the moment it’s to me to organize best and easy to use suite of logic nodes and make first tests … then it will be fun and up to you to make tests in several games, robotics … and improve with experiences and follow what’s happening in science. It’s a domain in very fast evolution and passionant… maybe one thing I have to do and you like to help me is a scoring in the tank game, and avoid a tank to fall outside; another is to transform the camera picture in dark/white pixels and with only interesting things for the state of the game
When you finish your nobes can you release them for us ( non coder)
@Chris.k Yes the objective is to be used by non coder too and mainly by graphist, designers (game, systems), automation engineers …
If it’s sucessfull I hope that the combination of the NNA (Deep Learning) and the RL (Reinforcement Learning) = DRLA will give us an innovative generalizable way for many domains to learn what are the best actions to do during a game, with a robot, a machine, the IoT, … the actions/states that can then be obtained in 3D environment like Armory are so huge that I am impatient to finish the logic nodes to see what you’ll imagine doing with them 
The development of the environment for the DRLA was longer than I expected with some random behaviors in Armory that @Lubos deals with in his bug stack. Thanks again to him!
Here is a small video to show you what I mean with this game environment tuning in Armory, ready soon to start the DRLA training (Neural Network moving actions management, game score management, environment capture)
https://1drv.ms/v/s!AkfR54v60DIDkIkIh4xREd0yAcypIw
Great to see Didier.
Oooh this is super interesting. Great work.
Might be something i play with in the future.
That’s done. This new kind of 3D Armory training environment for Deep Learning encourages now to test it on several others domain. The next will be enterprise 4.0.
Why is it better ?
Actual state :
The current DRLA is a mix between:
The actual node trees for the scene tank1 object :
My actual list of nodes, mainly used by the DRLA :
'''Add custom nodes'''
add_node(ArrayLoopIndiceWaitNode, category='Logic')
add_node(StringToArrayNode, category='Array')
add_node(MaterialNamedNode, category='Variable')
add_node(SetMaterialSureNode, category='Action')
add_node(PrintCRNode, category='Action')
add_node(StringSpecialNode, category='Variable')
add_node(GateTFNode, category='Logic')
add_node(StringSeparationNode, category='Variable')
add_node(StringSplitToArray, category='Variable')
add_node(PlaySetTilesheetNode, category='Animation')
'''pour le Deep Learning'''
add_node(NNJsonGetNode, category='Logic')
add_node(NNFactoryNode, category='Logic')
add_node(NNHiddenLayerNode, category='Logic')
add_node(NNNetworkActNode, category='Logic')
'''pour le Deep Reinforcement Learning'''
add_node(RLMetteurEnSceneNode, category='Logic')
add_node(RLActionNode, category='Logic')
add_node(RLEpsilonNode, category='Logic')
add_node(RLGameNode, category='Logic')
add_node(RLEnvironmentNode, category='Logic')
add_node(RLStateNode, category='Logic')
add_node(RLAgentTrainingNode, category='Logic')
add_node(RLAgentActiveNode, category='Logic')
add_node(RLBatchLearnNode, category='Logic')
add_node(RLPredictNode, category='Logic')
# add_node(RLReplayExtractNode, category='Logic')
add_node(RLReplayToMemNode, category='Logic')
add_node(RLReplayLoopNode, category='Logic')
add_node(RLBatchNode, category='Logic')
add_node(RLQsaNode, category='Logic')
add_node(RLStoSANode, category='Logic')
add_node(RLCameraNode, category='Logic')
add_node(RLOnRenderNode, category='Event')
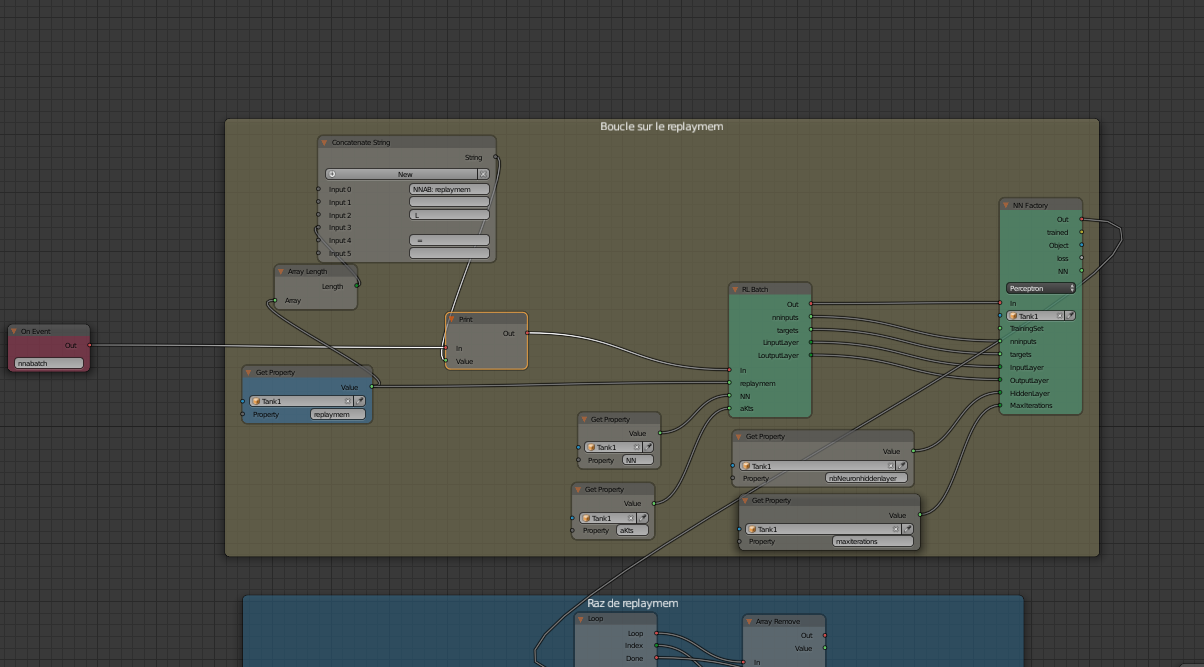
Therafter an example of an important node tree: the one in charge of rereading batches / rounds / episodes registered during the training and adjust the weights inside the Neural Network accordingly
Actually, I test the DRLA on Tanks and adjust some haxe code parts and try to find the best parameters to use (accuracy, speed, memory size, …).
I need too to develop new tools that will help to visualize how the DLRA improves during the training (that is to say the speed of its positioning and shooting on tanks2 during a new round).
But I can already say that Armory is fantastic because it allows me to make a very fast DRLA, and that the memory footprint is reduced and allows to consider very large layers in the NN.
(welcome  if you have infos on how to make Armory /Haxe /Kha optimizations with GPU Nvidia ?)
if you have infos on how to make Armory /Haxe /Kha optimizations with GPU Nvidia ?)
In addition, the architecture in logic nodes makes it possible to quickly modify / test various solutions, while facilitating readability and reusability.
Another important point and not least, its stability because after several hours of tanks training into Firefox browser, there is no crash to report ! Thanks @lubos for this top work.
(version with Blender 2.8 with only some modifications applied to the getpixels code)
Another way is also opening for DLRA to fuel an art movement based on neural art, using techniques such as DeepDream, Style Transfer and feature visualization. By reading this excellent document you will know more and understand how this could become disruptive in the way we will design higher quality 3D textures. https://distill.pub/2018/differentiable-parameterizations/
Looks really promising!
Are you planning to release this as open source (or even provide it as pull request for the Armory3D project)?
@NothanUmber
I need some more time to test/optimize some code, understand the bests tuning with the DRLA parameters, as well as develop tools that will help everyone to understand and have the possibility to follow the DRLA progress during a training. Maybe very simple tool as a first step …
What I would hope it’s we could start a kind of ecosystem of passionates around Neural Networks in the 3D environment Armory that would like to start real application projects. Do you think it’s possible ?
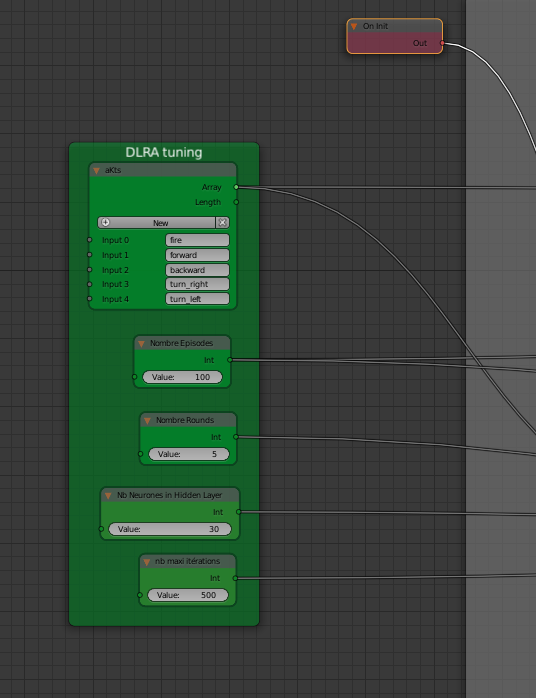
That’s done. Tuning the initial parameters and looking results with indicators gives me a better understanding of how the training of the Neural Network behaves
I start a Youtube chaine here https://youtu.be/ef-S7M6_yEowhere
You will find the first video, that is an overview.
I name it ATRAP.
I hope those videos will create some motivations to participate to the adventure.