That’s done for a first step in experimenting if this OOP with Armory “tient la route”.
This first step to test proposal is done by creating several Factory Class able to create instanciation of different Classes, taking the exemple of the Neural Network.
Here an exemple of result when printing the Neurones of each Layer, that is here the Container Collections of the scene.
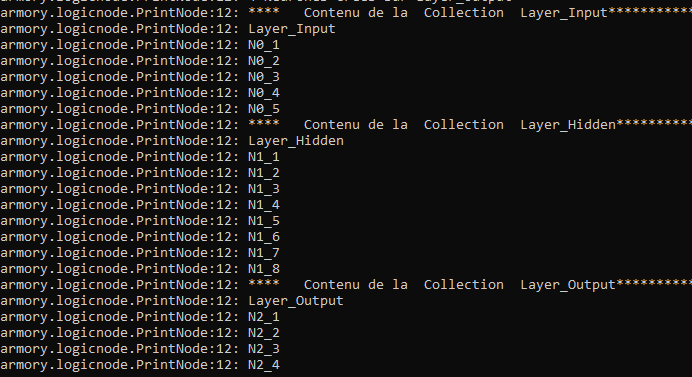
Thus this first step shows that in this first OOP rules proposal :
1 + 2 is OK we have logic nodes to add a new collection in the active scene. Then Objects are added inside a collection simply by using an add Array logic node, with the Collection as the input Array.
3 + 4 + 5 is OK we have a Class Factory able to create 3D objects, where each object represents an instanciation of a Class. Each Factory class Methods are realized thanks to the logic node Function
made by @zicklag
6 is TBC as it needs now to be test further on, in order to confirm/define some rules to reproduce OOP inheritance.
I modify with 4. A Class is an Empty or a standard mesh object.
And always what’s amazing about Armory is that it’s very fast, even with a lot of neurons. Indeed, we could fear an additional cost of CPU time with a switch to OOP.
It seems to me that on the contrary with this first test, if I compare it with other realizations, it would allow to reduce the number of Logic Nodes, to use more native Blender possibilities and thus to gain even more in performance.
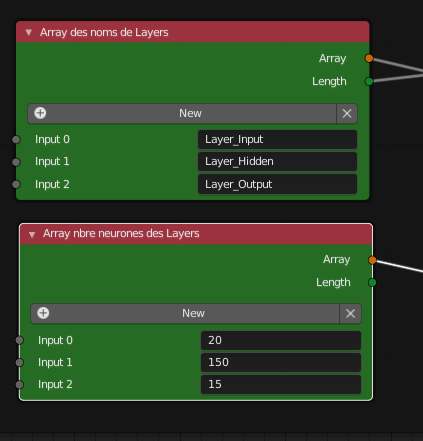
See therafter picture for a load test

For the next step, I will test a behavior well known in OOP, that is Observateur/Observable, and thus go deeper with point 6 of the OOP proposal for Armory.
Next step:
6 is now tested OK
Done by adding several “Observateurs” to an “Observable”, using a Method belonging to a child Class of the parent Class.
The technic used is as follow :
-
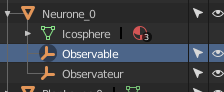 The generic Class Neurone_0 has 2 children, that is 2 “Empty” Observateur and Observable
The generic Class Neurone_0 has 2 children, that is 2 “Empty” Observateur and Observable -
when I want to call the Method M_AjouterObservateur on an instance of the Neurone_0 (that is the objects created by the Factory of Neurones), I have to call the Method of it’s children Class Observable, that is in fact a specialized Class that has this Method. Thus all needed Observateurs become registered for this Neurone.
-
for example on the following system console picture, the method M_AjouterObservateur is called here with the following resulting print that shows that effectively the tab of the Observable, that is in this case for the neurone N0_1 (= Neurone 1 of the Layer Input ) register observateurs of the following Layer.
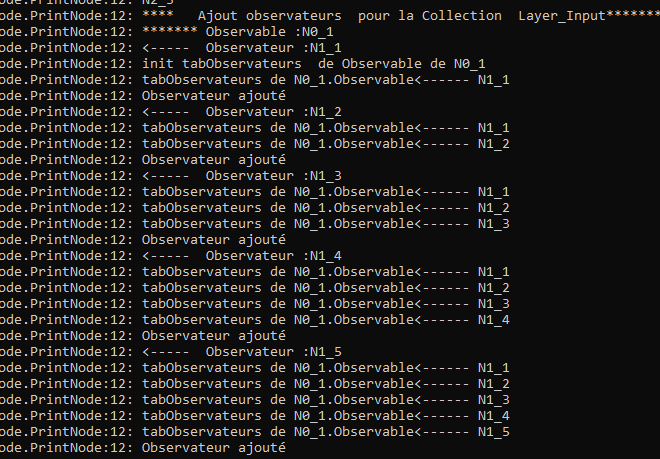

![]()
After a few days of tests with OOP method for Armory SW dev … some news:
-
The new Neural Network made using this OOP approach is coming to life. See picture below
-
I discover using it that this OOP approach proposal gives great advantage in the lisibility of the application.

For example, when you clic on an object (that is a Class) into a Scene, as you see directly what are the Methods of it into the Armory Traits window, thus you kickly see what is the Logic Node Tree to select in order to modify the behavior of a Class. (for example here it’s about +15 traits and +12 Class, and the quantity of logic Nodes is divided by an approximate factor of +20 compared to a functional approach thanks to inheritance capabilities )
Hopping that you will find it usefull for you too and that you will soon give us some info on your own tests of this OOP proposed method for SW Dev within Armory.
News: I focus the design approach to get a best how-to with it for some things like to keep performances too in this OOP approach (as it was the case when using array of array of array in preceeding tests) that is to keep good alignment of datas in memory, keep cache friendly things and maximize the use of SIMD for example.