That’s done. This new kind of 3D Armory training environment for Deep Learning encourages now to test it on several others domain. The next will be enterprise 4.0.
Why is it better ?
- you don’t need any training data, as it is the DRLA (Deep Reinforcement Learning Armory) that plays, registers and trains the NN (Neural Network) itself in the 3D environment.
- once the NN is trained, the file can be exported to a real target.
Actual state :
The current DRLA is a mix between:
- the readability offered by the logic nodes and Traits in Armory,
- the compactness of the code encapsulated in a specific node DRLA
The actual node trees for the scene tank1 object : 
My actual list of nodes, mainly used by the DRLA :
'''Add custom nodes'''
add_node(ArrayLoopIndiceWaitNode, category='Logic')
add_node(StringToArrayNode, category='Array')
add_node(MaterialNamedNode, category='Variable')
add_node(SetMaterialSureNode, category='Action')
add_node(PrintCRNode, category='Action')
add_node(StringSpecialNode, category='Variable')
add_node(GateTFNode, category='Logic')
add_node(StringSeparationNode, category='Variable')
add_node(StringSplitToArray, category='Variable')
add_node(PlaySetTilesheetNode, category='Animation')
'''pour le Deep Learning'''
add_node(NNJsonGetNode, category='Logic')
add_node(NNFactoryNode, category='Logic')
add_node(NNHiddenLayerNode, category='Logic')
add_node(NNNetworkActNode, category='Logic')
'''pour le Deep Reinforcement Learning'''
add_node(RLMetteurEnSceneNode, category='Logic')
add_node(RLActionNode, category='Logic')
add_node(RLEpsilonNode, category='Logic')
add_node(RLGameNode, category='Logic')
add_node(RLEnvironmentNode, category='Logic')
add_node(RLStateNode, category='Logic')
add_node(RLAgentTrainingNode, category='Logic')
add_node(RLAgentActiveNode, category='Logic')
add_node(RLBatchLearnNode, category='Logic')
add_node(RLPredictNode, category='Logic')
# add_node(RLReplayExtractNode, category='Logic')
add_node(RLReplayToMemNode, category='Logic')
add_node(RLReplayLoopNode, category='Logic')
add_node(RLBatchNode, category='Logic')
add_node(RLQsaNode, category='Logic')
add_node(RLStoSANode, category='Logic')
add_node(RLCameraNode, category='Logic')
add_node(RLOnRenderNode, category='Event')
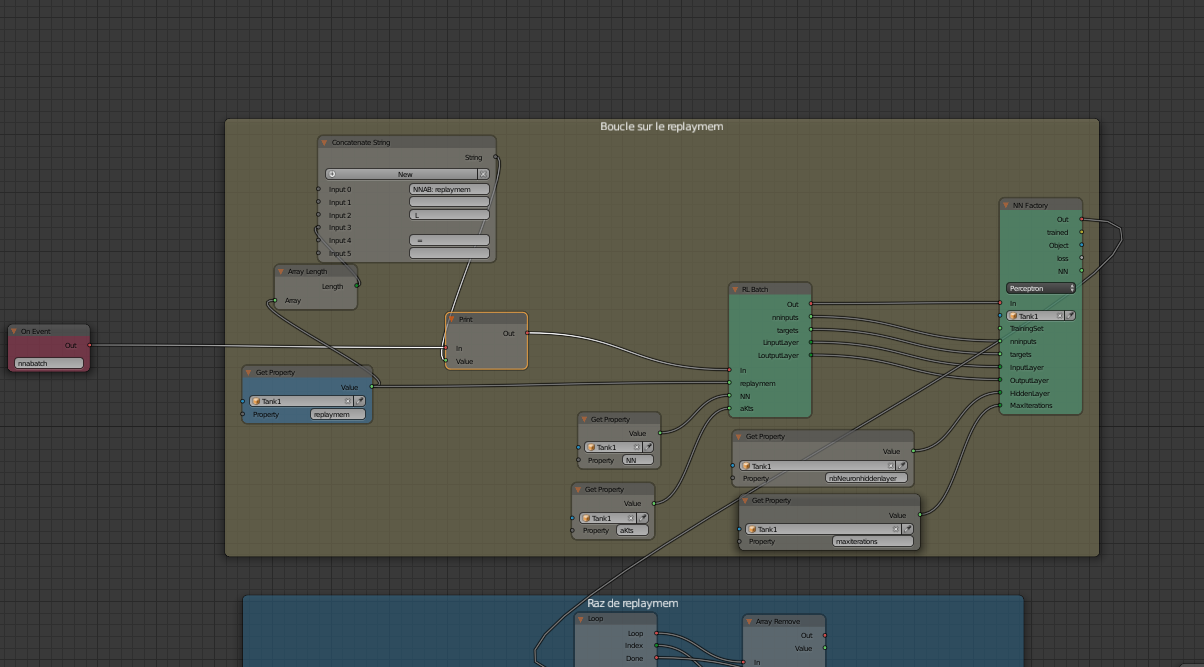
Therafter an example of an important node tree: the one in charge of rereading batches / rounds / episodes registered during the training and adjust the weights inside the Neural Network accordingly
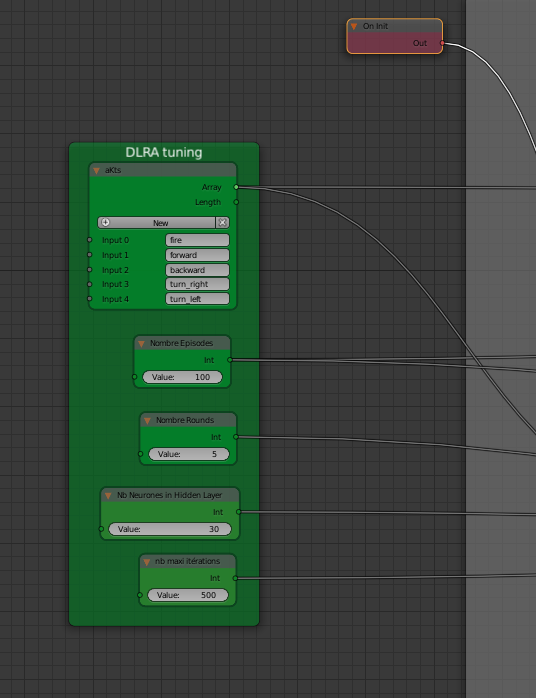
Actually, I test the DRLA on Tanks and adjust some haxe code parts and try to find the best parameters to use (accuracy, speed, memory size, …).
I need too to develop new tools that will help to visualize how the DLRA improves during the training (that is to say the speed of its positioning and shooting on tanks2 during a new round).
But I can already say that Armory is fantastic because it allows me to make a very fast DRLA, and that the memory footprint is reduced and allows to consider very large layers in the NN.
(welcome  if you have infos on how to make Armory /Haxe /Kha optimizations with GPU Nvidia ?)
if you have infos on how to make Armory /Haxe /Kha optimizations with GPU Nvidia ?)
In addition, the architecture in logic nodes makes it possible to quickly modify / test various solutions, while facilitating readability and reusability.
Another important point and not least, its stability because after several hours of tanks training into Firefox browser, there is no crash to report ! Thanks @lubos for this top work.
(version with Blender 2.8 with only some modifications applied to the getpixels code)