@MagicLord Please look here for first tests with NN training in the simple tanks game template that you know https://youtu.be/zlhQTxwBSnQ or https://youtu.be/ef-S7M6_yEo


The 2 main logic nodes at the center of the NN training
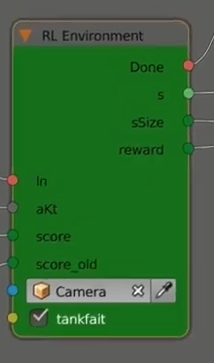 and
and 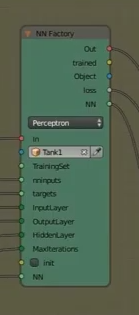
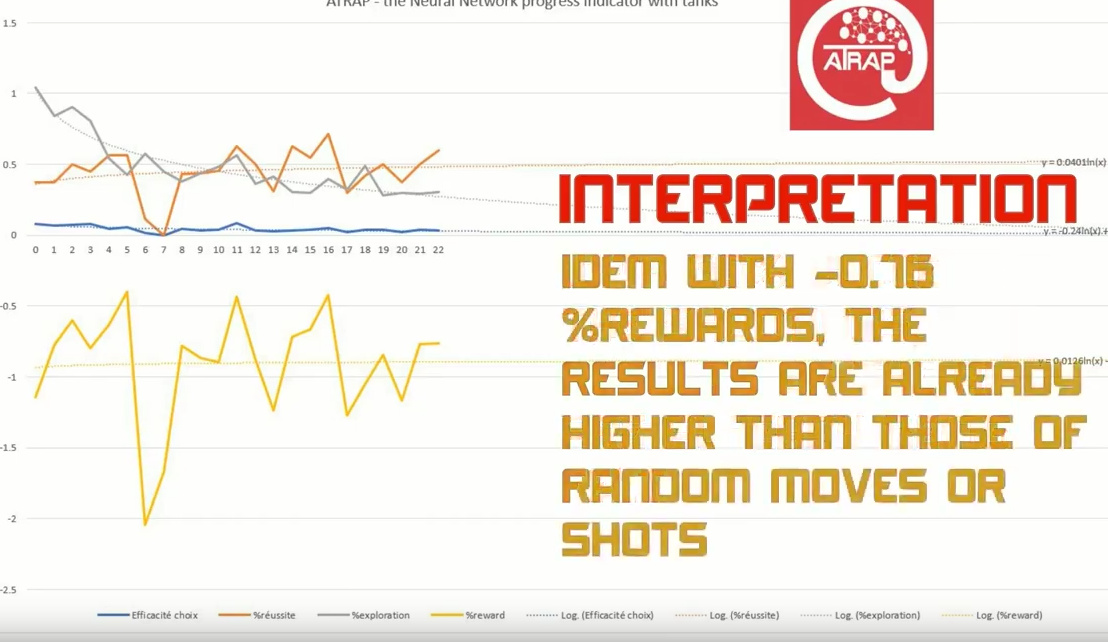

Is it not enough in your opinion to respond to your remark, as I interpret your remark as the need to have a feasibility study result / demonstration model to show  ?
?
(My hope is to create motivation of some passionates to use this technology that I encapsulate through the name ATRAP (actually kick and dirt  that I am busy at reusing and adapt/optimizing it for a test on Inverse Kinematic for Robot arm ), and to give the help needed for an open-game that must be defined see the discussion opened by @trsh here Ongoing projects that need help… sharing ideas and feasability welcome)
that I am busy at reusing and adapt/optimizing it for a test on Inverse Kinematic for Robot arm ), and to give the help needed for an open-game that must be defined see the discussion opened by @trsh here Ongoing projects that need help… sharing ideas and feasability welcome)